탐험적 데이터 분석
Exploratory Data Analysis
April 22, 2017
아래는 Hadley WickhamR 사용자들이 지금까지 가장 많이 내려받은 패키지인 dplyr와 ggplot2를 만든 사람입니다.이 지은 R for Data Science 1장과 2장에 있는 그림입니다. 이 글에서는 아래의 그림에 나타난 순서대로 탐험적 데이터 분석의 각 과정을 소개하고 특별히 모델링에 관한 내용을 강조하겠습니다.아주 짧게 결론부터 이야기하면, 이 모델링에서 가치가 창출되기 때문입니다. 구체적인 내용은 아래에서 다루겠습니다. 그리고 일반적인 과학 활동보다는 비즈니스 상황에서 데이터 과학자가 일하는 방식, 겪게되는 상황 등을 위주로 다루겠습니다.
이 그림은 미국 Creative Commons Attribution-NonCommercial-NoDerivs 3.0 라이선스에 의해 보호 받고 있습니다. 이 그림은 상업적으로 이용할 수 없고, 재조합하거나 변형해서 배포할 수 없습니다.
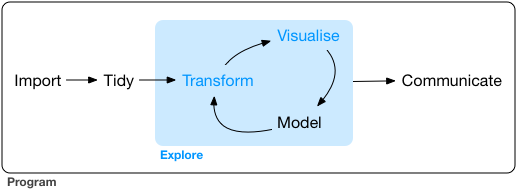
그림에서 왼쪽부터 번호를 붙여 하나씩 살펴보겠습니다.
- 1. 부르기 Import
- 2. 깔끔하게 만들기 Tidy
- 3. 바꾸기 Transform
- 4. 시각화 Visualise원문 그림을 따라 Visualize 대신 영국식 영어 철자 Visualise 로 표기합니다.
- 5. 모델링 Model
- 6. 소통 Communicate
데이터 과학자라면 학문적인 배경흔히 비즈니스 상황에서 데이터 과학자가 될 수 있는 학문적인 배경에는 컴퓨터 과학/공학/전산학, 통계학, 생물학, 물리학, 수학 등이 있습니다. 수학과 컴퓨터를 잘한다면 경제학이나 사회학도 가능합니다. 물론, 보유 기술과 연구 주제에 따라 자세한 구분이 필요합니다.에 상관 없이 주로 위의 순서로 일합니다. 모든 단계가 중요하지만 탐험적 데이터 분석의 핵심이라고 할 수 있는 3번부터 5번이 특별히 더 중요합니다. 그럼 이제 각 단계를 하나씩 살펴보겠습니다.
1. 부르기 Import
당연하게도 데이터를 불러오지 않으면 데이터가 있을 수가 없습니다. 이 과정이 없으면 데이터 없는 데이터 과학자가 됩니다. 데이터 엔지니어(Data Engineer)가 불러오는 작업을 맡는 경우에는 데이터 과학자가 직접 불러오지 않아도 됩니다. 직접 맡지 않더라도 풀려고 하는 비즈니스 문제이 부분에 관하여 더욱 자세한 논의는 김진철 님께서 CIO Korea에 기고하신 글을 참조하시길 바랍니다.에 맞는 데이터를 불러오도록 충분한 협의가 필요합니다. 협의 과정에서 해당 문제를 풀 때 필요한 데이터가 없다는 것을 알게 될 수도 있습니다. 이렇게 데이터가 부족한 경우에는 의뢰인과 협의하며 풀려는 문제를 수정해야할 수도 있습니다.
문제를 구체적으로 잘 정하는 것은 아무리 강조해도 지나치지 않을만큼 정말 중요합니다. 과정의 시작부터 잘 정하지 못하더라도 탐험적 데이터 과정을 통해 문제를 수정하거나 이상한 데이터를 찾을 수도 있습니다. 어떤 경우에는 처음 정한 문제에만 딱 맞게 데이터를 불러와서 문제가 수정되었을 때 데이터가 큰데도 새로 불러와야 하는 경우가 생깁니다. 따라서 가능한 변수의 합집합을 미리 추리면서 쓸모 없는 변수를 정성적으로 쳐내는 과정도 중요합니다.
2. 깔끔하게 만들기 Tidy
이 Tidy 과정은 분석하기 좋도록 깔끔하게 만드는 과정입니다. 단순한 원본 데이터를 단순하게 정리data cleaning하는 것보다 체계적인 의미가 있습니다. 1번 과정처럼 2번 과정 역시 데이터 엔지니어가 맡는다면 데이터 과학자가 직접 하지 않아도 됩니다.
분석하기 좋도록 깔끔하게 만든 데이터는 다음과 같은 성질이 있습니다.출처: Hadley Wickham, "Tidy Data", The Journal of Statistical Software, 59 (2014).
- 1. 각 변수가 한 열을 구성합니다.
- 2. 각 관측이 한 행을 구성합니다.
- 3. 각 관측 단위의 종류가 하나의 표를 구성합니다.
위의 성질을 이해하는데 도움이 되도록 아래에 표 3개Hadley Wickham이 논문에서 사용했던 예제 표 3개를 한글로 옮긴 것입니다.를 인용하였습니다. 바로 아래에 있는 표1에는 사람마다 처방 종류에 따라 결과값이 있습니다.
| 처방a | 처방b | |
|---|---|---|
| 사람1 | - | 2 |
| 사람2 | 16 | 11 |
| 사람3 | 3 | 1 |
아래의 표2는 위의 표1에서 가로와 세로만 뒤집은 것입니다.
| 사람1 | 사람2 | 사람3 | |
|---|---|---|---|
| 처방a | - | 16 | 3 |
| 처방b | 2 | 11 | 1 |
표3은 표1과 표2에서 사용한 것과 정확하게 같은 데이터를 나타낸 것입니다. 하지만 표1과 표2와는 다르게, 표3에서는 변수마다 열을 이루고 각 관측값이 행을 이룹니다.
| 이름 | 처방 | 결과 |
|---|---|---|
| 사람1 | a | - |
| 사람2 | a | 16 |
| 사람3 | a | 3 |
| 사람1 | b | 2 |
| 사람2 | b | 11 |
| 사람3 | b | 1 |
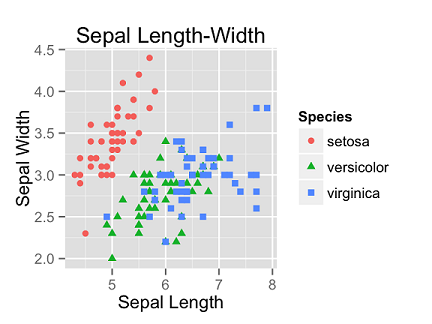
표3과 같이 나타내면 여러 가지 장점이 있겠습니다만 한 가지만 들어보겠습니다. Iris data를 가지고 그린 아래 그림에서처럼 종(Species)마다 색을 입혀서 종별로 패턴을 비교할 수 있게 됩니다.
3. 바꾸기 Transform
이 단계부터가 본격적인 탐험적 데이터 분석 과정입니다. 파이썬 pandas 라이브러리 문서의 Group By 항목에서 설명하는 것처럼, 무리지어 종합하거나, 수학적으로 값을 적절히 변환하거나, 데이터에서 일부를 추출할 수도 있습니다. 문제를 풀려고 세운 가설을 검증하는데 도움이 될만한 패턴을 찾기 위해서 이런 작업을 합니다. 이 단계를 종종 여러번 수행하기 때문에 데이터가 너무 클 때는 전체 데이터를 가지고 하기보다는, 데이터 전체를 대표하는 항목들을 가지고 합니다. 또는 데이터 전체를 대표하는 항목을 여러번 골라서 통계적인 분석을 수행하기도 합니다. 다양한 방법 중에서 문제를 풀려고 세운 가설에 적합한 방식을 고릅니다.
4. 시각화 Visualise
이 과정에서는 변수 각각의 통계적인 패턴을 보기도 하고, 변수마다 나타나는 통계적인 패턴을 서로 비교하기도 합니다. 또는 이러한 패턴의 시간적인 변화를 보기도 합니다. 이 역시 문제를 풀려고 세운 가설을 검증하는데 도움이 될만한 패턴을 찾기 위해서 이런 작업을 수행합니다. 때때로 같은 데이터라도 시각화 방법에 따라 다른 직관을 줄 수도 있기 때문에 같은 데이터를 다양한 방식으로 여러번 그리기도 합니다. 시각화 방식에 따라 잃는 정보의 수준이 다를 수도 있습니다. 이 4번째 단계에서 특이하거나 이상한 값을 발견하기도 합니다.이러한 상황이 생기면 3단계를 다시 수행하거나 심각하면 1단계부터 다시 해야할 수도 있습니다. 데이터 과학자의 숙련도에 따라, 데이터 속에서 적절한 패턴을 찾기 위해 헤메는 시간이 줄어들 것입니다.
바꾸기 단계를 거쳐 시각화 단계까지만 와서 작업을 멈춘다면 다음과 같은 이야기를 들을 것입니다. "So what!? 그래서 어쩌자는 겁니까?" 반드시 설명을 하기 위해서는 모델링이 필요합니다. 설명이 있어야 정량적인 기준이나 예측이 따라 나옵니다.
5. 모델링 Model
모델링 과정은 탐험적 데이터 분석의 핵심이고 데이터 과학자의 역할이라고도 할 수 있겠습니다. 데이터에서 나타나는 패턴을 설명하는 과정입니다. 데이터를 산더미 같이 많이 모으는 것은 기술적으로는 대단한 일이고 중요한 일입니다. 하지만 그 데이터 자체만으로는 별 의미가 없습니다. 데이터를 많이 모으는 것은 데이터 과학자의 정체성이 아닙니다. 결국에는 잘 설명해야합니다. 데이터를 설명하지 않는 것은 뭔가를 지을 때 건축 자재를 일단 몽땅 가져다 놓기만 하고 아무일도 하지 않는 것과 같습니다. 열심히 모은 데이터를 체계적인 설명해야 정량적인 기준이나 예측이 따라 나올 수 있습니다.물론, 엉뚱한 데이터를 쓸데없이 많이 모으기만 하면 안 나오겠습니다.
잘 설명하려면 먼저 문제를 분명하게 정하는 것이 중요합니다.
이미 알려진 시스템에 관한 설명을 많이 알고 있으면, 다루고 있는 시스템에서 나타나는 현상과 비교하여 비유를 통해 잘 설명할 수도 있습니다. 꼭 정량적인 설명이 아닐 수도 있습니다. 융합적인 생각이 중요할 수 있습니다.

또한 세련된 설명은 위의 그림에서 다빈치와 아인슈타인의 말과 같이 단순해야한다고 생각합니다.물론, 너무 단순해서 설명을 잘 못하면 안 되겠습니다. 복잡해지면 유지 보수 운영 측면에서 걷잡을 수 없는 혼란에 빠지기 쉽상입니다. 처음부터 모델을 복잡하게 세우면, 잘 세웠다면 유지 보수 운영하는 사람들이 굳이 하지 않아도 될 일이 생깁니다. 다루는 시스템에서 굳이 넣을 필요 없는 수학적인 방법을 몽땅 때려 넣고 온갖 조건문으로 뒤범벅되어있는 스파게티 모델스파게티 코드와 비슷한 의미에서 사용했습니다.을 피합시다!
이는 회사를 다니면서 궁극의 법칙을 찾자는 이야기가 결코 아닙니다. 비즈니스 상황에서는 모델이 adaptive하고 flexible 해도 괜찮습니다. 기업에 커다란 손해를 끼치 수 있는 스파게티 모델을 피하자는 것입니다. 이것을 어떻게 피해야 하겠습니까? 먼저, 데이터 과학자 본인이 통계, 수학 등 이론적인 부분을 챙기면서 꾸준한 프로젝트 참여를 통해 뒤처지지 않아야겠습니다. 소속 회사에서 동료 데이터 과학자들과 함께 자신의 모델링 과정을 peer review 받는 것도 훌륭하게 모델링할 때 도움이 될 것입니다.
그렇다고 데이터 과학자 혼자 노력한다고 해서 스파게티 모델이 반드시 생기지 않는 것은 아닙니다. 데이터 과학 업무를 의뢰하는 회사나 담당자로부터 마케팅 측면에서 말도 안되는 방식으로 수학적인 기법을 무리하게 동원하도록 압박을 받아서 강제로 생기기도 합니다.의뢰하는 측은 "우리 회사도 (요즘 유행하는) A라는 기법을 사용하여 혁신을 이뤄냈습니다!"라고 말하고 싶어하는 과도한 욕심을 자제할 필요가 있습니다. 보통 이런 참사는 의뢰하는 고객사가 인건비 때문에 데이터 과학자를 운용하기 힘든 기업인 경우보다는, 고객사가 경제적으로 풍족하고 특정 업종을 선도하는 기업인 경우에 일어납니다. 물론, 자체적으로 데이터도 많고 데이터 과학자를 운용할 경제적인 여유가 있으면 좋겠지만 모두가 이와 같을 수 없습니다.
약간 벗어나는 다른 이야기지만, 모델링과 관련 있는 짧은 일화를 하나 소개하려고 합니다. 비즈니스 상황에서는 탐험적 데이터 분석 과정을 통해 단순하고 세련된 모델을 세우면 "그건 저도 할 수 있겠습니다"라고 무시하는 투가 섞인 말을 듣는 경우도 있습니다. 결코 쉽지 않은 과정을 통해서 얻은 결과인데도 말입니다. 때로는 학계에서 사용하던 기법에 비해 덜 복잡하다는 의미에서나 구현하는데 시간이 덜 든다는 의미에서 쉽다고 말하면, 듣는 사람들이 순진하게 곧이곧대로 받아들여 전문가가 아니더라도 누구나 쉽게 할 수 있는 것처럼 오해받는 경우도 있습니다.
여기까지가 Transform, Visualise, Model (TVM) 으로 정리할 수 있는 Exploratory Data Analysis (EDA)의 핵심 내용입니다. 이렇게 의미있는 패턴이나 특징을 찾아내기 위해서 다양한 수학적인 양을 측정해서 보고 비교하는 TVM 과정은 보통 한 번에 끝나지 않을 수 있습니다.수행하는 데이터 과학자가 이미 잘 알고 있는 현상에 관한 데이터를 다룰 때는 비교적 수월할 것입니다. 반복될 수 있기 때문에 처음부터 모든 데이터를 가지고 TVM을 하기보다는 데이터를 잘 대표하는 표본을 가지고 작업한 다음에 일반화 합니다. 가볍고 빠르게 TVM을 반복하기 위해 Python Jupyter notebook이나 R Studio 등을 적절하게 사용하는 것을 권장합니다. 한편, TVM 과정을 여러번 반복하다보면 작성한 코드나 얻은 부산물/산출물 등이 지저분하게 흩어지기 쉽습니다. 그래서 구현, 유지, 보수 등이 어렵게 됩니다. 처음부터 알아보기 쉽게 정리한다면 이후에 넘겨 받는 사람에게 굳이 하지 않아도 될 번거로운 일이 생기지 않을 것입니다.
6. 소통
이 과정에서는 설명한 결과를 가지고 의뢰한 회사나 담당자와 함께 이야기합니다.일방적인 보고가 될 수도 있겠지만 기존에 정성적으로 알고 있었거나 사용하고 있던 방식과 비교하기도 합니다. 3, 4, 5단계를 순서대로 거쳐 6단계에 도착하기보다는, 각 단계에서 언제든지 소통이 필요하면 이 단계로 넘어와서 다시 돌아갑니다. 해당 업종을 잘 알고 있는 데이터 과학자라면 이 단계를 덜 거치겠지만, 그렇지 않은 경우에는 열린 마음으로 이 과정을 많이 거치는 것이 모두가 만족할 수 있는 결과로 이어질 것입니다.